 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
MMDetection: Open MMLab Detection Toolbox and Benchmark
Jun 17, 2019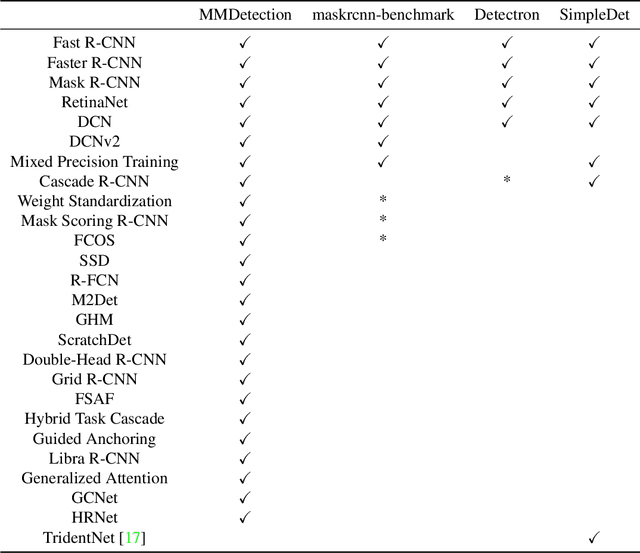
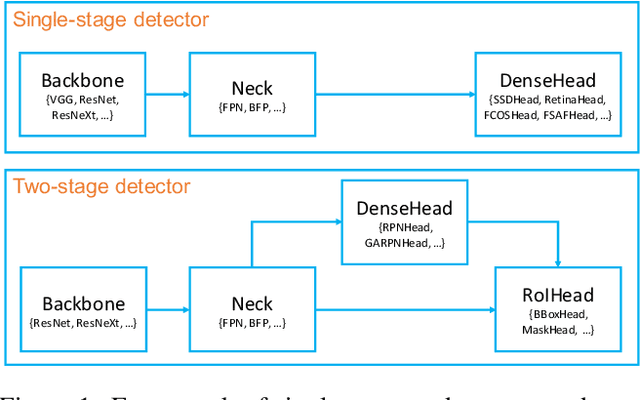
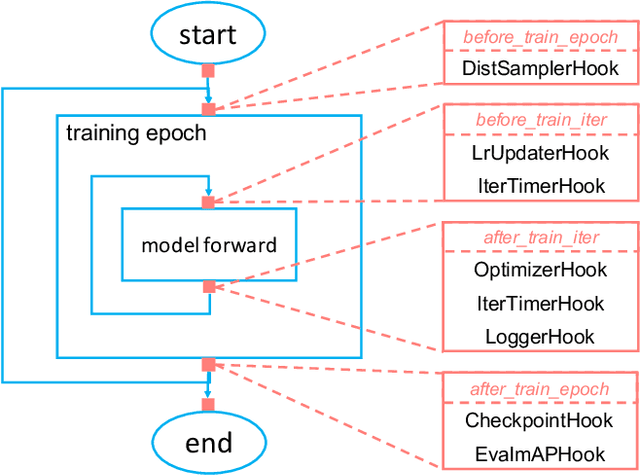
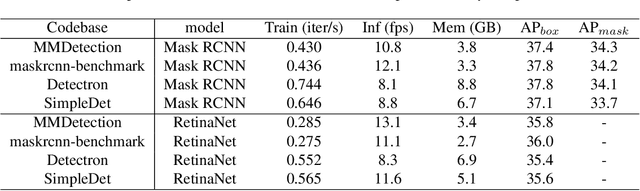
We present MMDetection, an object detection toolbox that contains a rich set of object detection and instance segmentation methods as well as related components and modules. The toolbox started from a codebase of MMDet team who won the detection track of COCO Challenge 2018. It gradually evolves into a unified platform that covers many popular detection methods and contemporary modules. It not only includes training and inference codes, but also provides weights for more than 200 network models. We believe this toolbox is by far the most complete detection toolbox. In this paper, we introduce the various features of this toolbox. In addition, we also conduct a benchmarking study on different methods, components, and their hyper-parameters. We wish that the toolbox and benchmark could serve the growing research community by providing a flexible toolkit to reimplement existing methods and develop their own new detectors. Code and models are available at https://github.com/open-mmlab/mmdetection. The project is under active development and we will keep this document updated.
An Empirical Study of Spatial Attention Mechanisms in Deep Networks
Apr 11, 2019

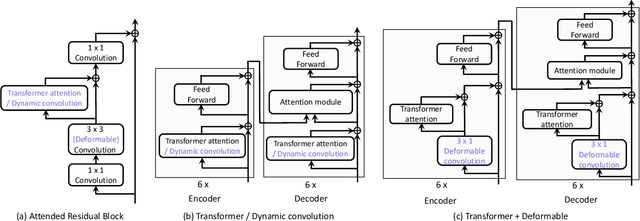
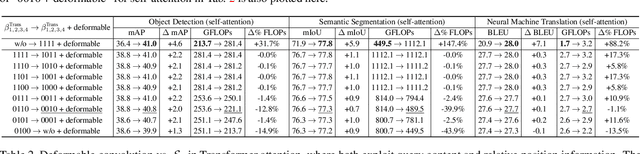
Attention mechanisms have become a popular component in deep neural networks, yet there has been little examination of how different influencing factors and methods for computing attention from these factors affect performance. Toward a better general understanding of attention mechanisms, we present an empirical study that ablates various spatial attention elements within a generalized attention formulation, encompassing the dominant Transformer attention as well as the prevalent deformable convolution and dynamic convolution modules. Conducted on a variety of applications, the study yields significant findings about spatial attention in deep networks, some of which run counter to conventional understanding. For example, we find that the query and key content comparison in Transformer attention is negligible for self-attention, but vital for encoder-decoder attention. A proper combination of deformable convolution with key content only saliency achieves the best accuracy-efficiency tradeoff in self-attention. Our results suggest that there exists much room for improvement in the design of attention mechanisms.
Integrated Object Detection and Tracking with Tracklet-Conditioned Detection
Nov 27, 2018
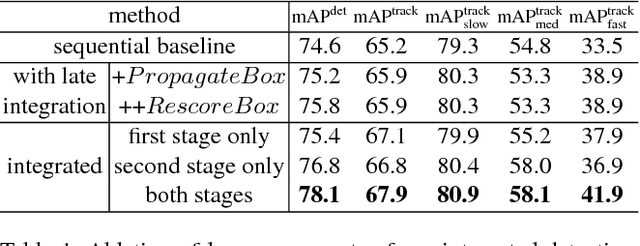


Accurate detection and tracking of objects is vital for effective video understanding. In previous work, the two tasks have been combined in a way that tracking is based heavily on detection, but the detection benefits marginally from the tracking. To increase synergy, we propose to more tightly integrate the tasks by conditioning the object detection in the current frame on tracklets computed in prior frames. With this approach, the object detection results not only have high detection responses, but also improved coherence with the existing tracklets. This greater coherence leads to estimated object trajectories that are smoother and more stable than the jittered paths obtained without tracklet-conditioned detection. Over extensive experiments, this approach is shown to achieve state-of-the-art performance in terms of both detection and tracking accuracy, as well as noticeable improvements in tracking stability.
ExFuse: Enhancing Feature Fusion for Semantic Segmentation
Apr 11, 2018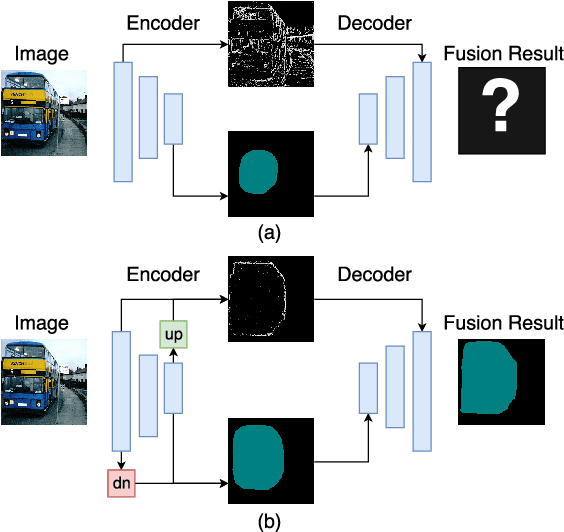
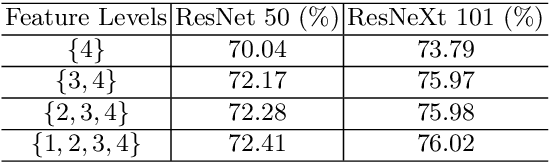
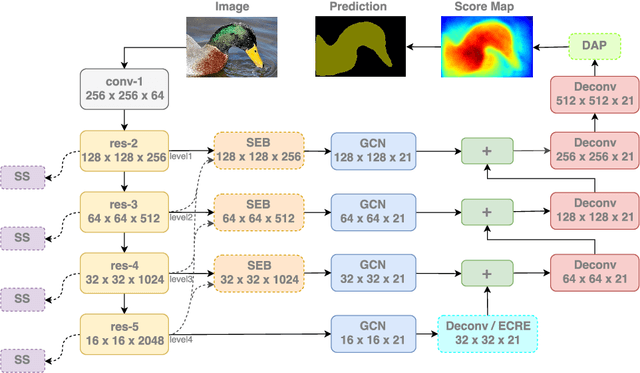

Modern semantic segmentation frameworks usually combine low-level and high-level features from pre-trained backbone convolutional models to boost performance. In this paper, we first point out that a simple fusion of low-level and high-level features could be less effective because of the gap in semantic levels and spatial resolution. We find that introducing semantic information into low-level features and high-resolution details into high-level features is more effective for the later fusion. Based on this observation, we propose a new framework, named ExFuse, to bridge the gap between low-level and high-level features thus significantly improve the segmentation quality by 4.0\% in total. Furthermore, we evaluate our approach on the challenging PASCAL VOC 2012 segmentation benchmark and achieve 87.9\% mean IoU, which outperforms the previous state-of-the-art results.